
ConfigRF — ML-Based Identification and Classification of Configuration Files
Tool · Research Tool
Focus: Identification and classification of deployment & runtime configuration files • Method: TF-IDF + Random Forest (Binary & Multi-class classification)
Synopsis
Modern software systems rely on complex configuration systems composed of multiple interconnected configuration files used during deployment and runtime. However, configuration files do not follow a strict standard and often share formats and extensions with regular source code files.
To address this challenge, we propose ConfigRF, a machine learning–based approach that:
- Automatically distinguishes configuration files from non-configuration files
- Classifies configuration files into nine empirically derived configuration types
Methodology
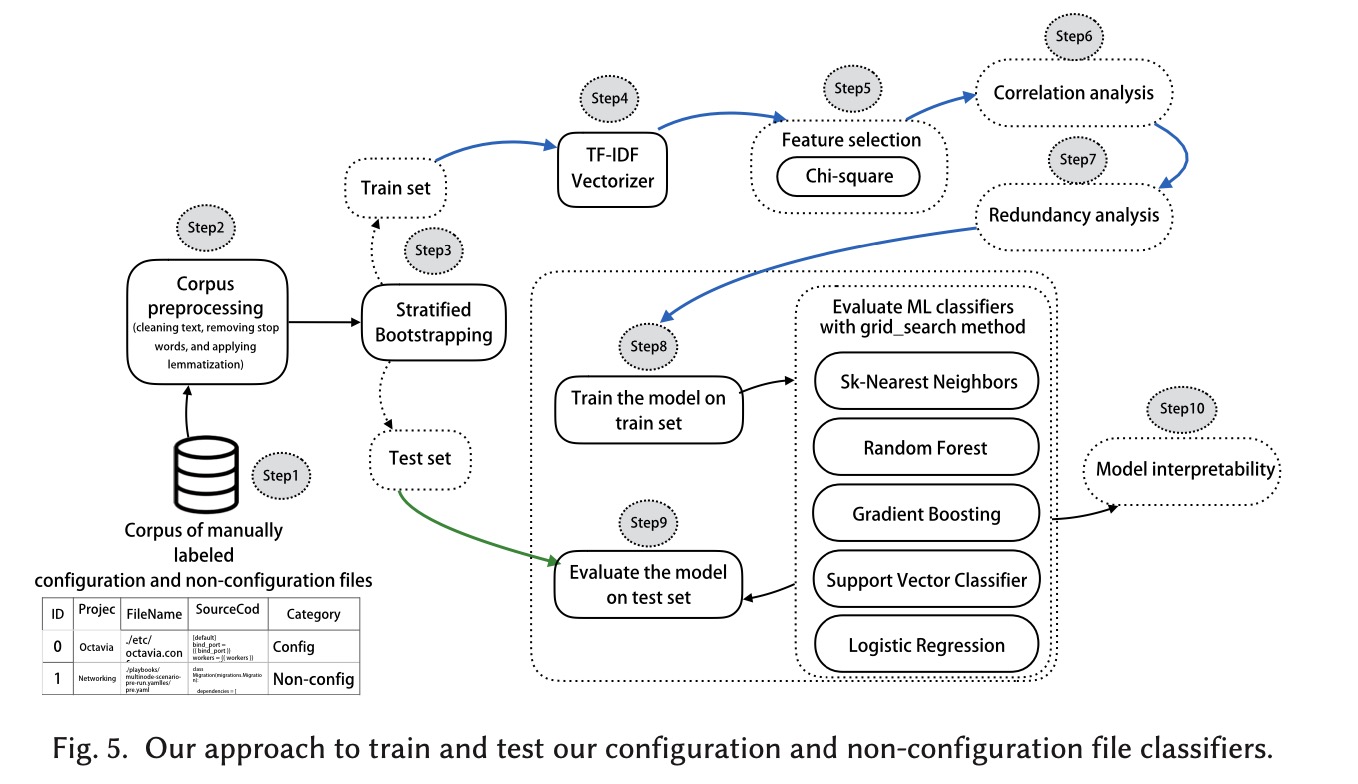
1 — Empirical Ground Truth Construction
A corpus of 1,756 manually analyzed configuration files was built using a mixed card sorting technique, identifying nine configuration categories. An additional 1,756 non-configuration files were curated to form a balanced dataset.
2 — Text Representation (TF-IDF)
Each file is transformed into a numerical vector using Term Frequency–Inverse Document Frequency (TF-IDF). TF-IDF assigns weights to terms based on their discriminative power across files, enabling the model to automatically learn configuration-related patterns.
3 — Feature Selection & Reduction
To improve robustness and avoid overfitting:
- Pearson’s Chi-square test is used for feature relevance selection
- Correlation analysis removes highly collinear features
- Redundancy analysis further reduces feature overlap
4 — Random Forest Classification
A Random Forest (RF) classifier is trained using stratified bootstrapping (100 bootstrap runs) to ensure statistical robustness. Two tasks are performed:
- Binary classification: Configuration vs. Non-configuration
- Multi-class classification: Classification into nine configuration types
Empirical Performance
Binary Classification (Configuration vs Non-Configuration)
• Median AUC: 0.91
• Median Brier Score: 0.12
• Median Precision: 0.86
• Median Recall: 0.83
Multi-Class Classification (Nine Configuration Types)
• Median Weighted AUC: 0.92
• Median Brier Score: 0.04
• Median Weighted Precision: 0.84
• Median Weighted Recall: 0.82
Remarkably, labeling as few as 100 files is sufficient to train a model achieving strong predictive performance.
• Median AUC: 0.91
• Median Brier Score: 0.12
• Median Precision: 0.86
• Median Recall: 0.83
Multi-Class Classification (Nine Configuration Types)
• Median Weighted AUC: 0.92
• Median Brier Score: 0.04
• Median Weighted Precision: 0.84
• Median Weighted Recall: 0.82
Remarkably, labeling as few as 100 files is sufficient to train a model achieving strong predictive performance.
Key Characteristics
- Handles heterogeneous file formats (.py, .yaml, .sh, .ini, .conf, etc.)
- Extension-agnostic (does not rely solely on file extensions)
- Robust to mixed configuration/source-code repositories
- Statistically validated via bootstrapping
- Supports research on full configuration systems rather than isolated files
Research Reference
Bessghaier, N., Sayagh, M., Ouni, A., & Mkaouer, M. W. (2023).
What Constitutes the Deployment and Runtime Configuration System? An Empirical Study on OpenStack Projects.
ACM Transactions on Software Engineering and Methodology (TOSEM).
DOI: https://doi.org/10.1145/3607186
What Constitutes the Deployment and Runtime Configuration System? An Empirical Study on OpenStack Projects.
ACM Transactions on Software Engineering and Methodology (TOSEM).
DOI: https://doi.org/10.1145/3607186
Download
Source code: https://github.com/stilab-ets/CongIdentification
Repository includes Labeled datasets, experimental scripts, and Trained models.